硅谷投资人王川:抄袭模仿让强者更强?
(1)
到陌生都市的游客,驻足街头寻找餐馆时,常常面临这样一个问题:
一家餐馆人满为患,热闹非凡; 隔壁另一家餐馆门可罗雀,只有两三个食客。
在没有其它更多信息的情况下,该到哪家餐馆吃?
如果你像大多数人一样, 答案是:选择那家人多的餐馆。
因为你没有能力迅速判断哪家餐馆更好,而其他人的选择,成了最可靠的指南。
这种行为模式的后果是,拥挤的餐馆生意越来越好. 人少的餐馆则长期萧条,倒闭的风险更大。
世上多有自命不凡者,为标榜自己的与众不同,常常不屑的评论同类说, “ *国人就是浮躁,爱扎堆!”
模仿/抄袭其他人的行为方式,究竟是愚蠢浅薄,还是聪明实用? 不爱扎堆,特立独行的个体,是否真的比爱扎堆的个体,有更多进化优势?
(2)
2007年,英国 St Andrews 大学的进化生物学家 Kevin Laland,决定通过公开悬赏一万英镑的方式,给这个问题寻找一个科学的答案。
他给全世界的学术界同仁发公开信:
“假设你在一个陌生的环境里,不知道哪里有好吃的,不知道如何从点 A到点 B,你会花时间自己调查呢,还是观察模仿其他人?如果模仿,你会模仿谁?你看到的第一个人吗,还是最常见的行为方式?你总是模仿呢,还是选择性的模仿?”
竞赛的规则,是以所谓的“多臂赌博机”(multi-armed bandit) 的数学模型为基础. 赌博机,也叫老虎机,赌徒在投掷硬币后,转动其把柄 (就是所谓的 “臂”)后, 马上可以看到自己的回报。
参赛者每一个回合的行动,可以有三个选择: 观察,探索和开发。
观察, 就是看别的参赛者的行为 (拨动了哪个老虎机?) 和相应的回报, 记录下来。
探索,就是随机尝试探索别的行为(老虎机)和相应的回报,记录下来。
开发,就是在自己记录下来的策略中选择,直接拨动一个老虎机,获得相应的回报。
每个老虎机的回报,不是完全固定,而会随时间推进,有一定几率会改变。
只有选择“开发”的行为时,才可以真正获得回报。参赛的程序,必须制定策略,分配多少时间去开发,探索或者是观察。参赛者,每个回合都有可能死亡,而其过去每个回合的平均回报越低,死亡被淘汰的概率就越大。
包括Laland 在内的大部分学者,在比赛开始前,预测胜出的策略,将会是模仿和探索的这两种学习方式的结合。
来自十六个国家的 104个参赛者,提供了他们的竞赛程序。经过一年多,两个阶段,几十万个回合的厮杀,来自加拿大的两个年轻研究生提交的一个叫做 discountmachine 的算法,意外地获得第一名。
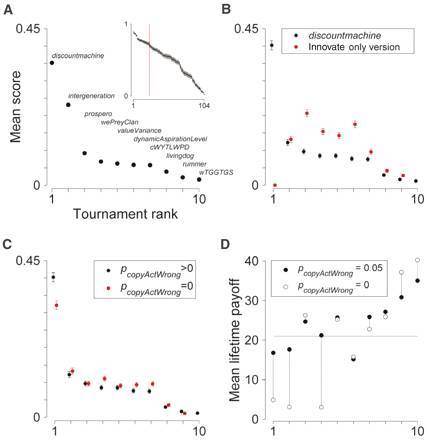
(配图来自 Rendell 和 Laland 2010年四月发表在“科学”杂志上的论文,"Why Copy Others?")
discountmachine 的策略,以“观察”为主,几乎完全不用“探索”的学习方式。即便在竞赛主持者调节各种环境参数后 (改变环境变化速度,改变观察信息失真或者无效的几率,改变可观测的其它个体的数目), 这个策略仍然在绝大多数情况下轻松击败其它对手。
事后分析,“观察”,作为一种社交学习方式,它的本质优势在于,观察到的社会其它成员的行为,有较大的几率是回报最高的选择,所以值得模仿。这种优势在相对稳定的环境里尤其突出。而“探索”获得的回报,统计平均上会趋于平庸,不利于建立进化优势。
唯一的例外,是环境变化速度极快的情况,这意味着老的行为模式的回报随时间流逝变化很大,简单的模仿抄袭完全丧失了价值。
生物界的扎堆现象,原来不是天生如此,而是进化淘汰的自然结果。那些总是特立独行者,大多很快耗尽自身资源而早夭。
(3)
美国学者,前哥伦比亚大学教授,Duncan Watts 2006年曾经做了一个实验:
他从网上召集了一万多名少年测试者,给他们一组 48 首不知名的歌曲的清单,观察他们下载试听歌曲的行为。测试者可以先试听音乐,然后决定是否下载歌曲。测试者分为两组,一组知道每首歌曲其他多少人下载 (A组), 另一组则什么都不知道 (B 组)。
没有多余信息的 B 组,48 首歌曲下载的分布是这样的:
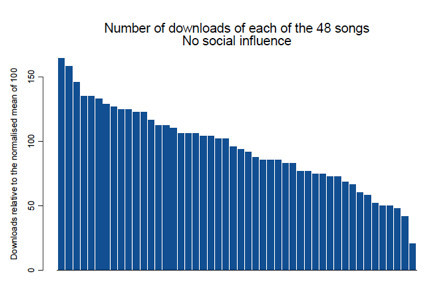
不同歌曲, 下载数目差别不大. 如果把中位数设为 100,下载数从 175 到 50以下,均匀分布。
而 A 组, 下载的分布是这样的:
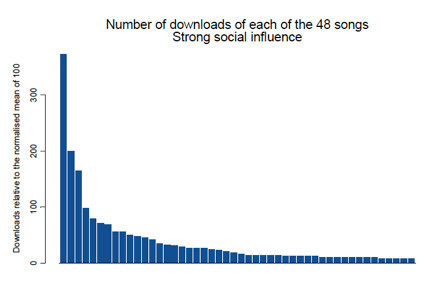
公开透明的信息,使个体迅速模仿他人的选择。模仿的结果,则是市场份额急剧向前几名倾斜。前几名吃肉,其他人只能喝汤。
这个现象在网络时代尤其突出. 美国有统计数字显示,谷歌(微博)搜索使用者 98%都只会点击前面三个搜索结果,而第一个搜索结果会得到 60% 的点击. 如果你在搜索结果排行前三名之外,不要说肉,连汤也很难喝上了。
(4)
进一步观察歌曲下载数的细节时,Watts 和他的团队又有新的发现:
歌曲下载数目的相对排序,两个对照组之间,并没有很强的关联。有更多信息后,最大的改变,来自于谁变成了第一名,谁变成最后一名。原先最热门的歌曲变得冷门的概率很小,最冷门的歌曲变得热门的概率也很小。
但是其它各种情况都有可能. 原先排名中间的歌曲,可能突然变成头牌,但更可能的是,排名跌倒最后,无人问津.
这个现象的后果让人不禁打了一个激灵:
一些行业涌现出来的成功者,很可能是因为这种个体模仿的网络效应所致. 其产品特性, 往往并不是最优秀的。
但成功者可能错误的把成功归因于产品特性。失败者则没有研究如何正确利用网络效应,而是开错了药方,继续埋头研究如何提高产品特性,但这并没有什么卵用。失败者长期陷入 "失败 - 开错药方 - 继续失败 - 继续用错药"的痛苦怪圈内苦苦挣扎,无法自拔。
(5)
实际上,对于群体抄袭模仿的行为导致的正反馈现象,匈牙利数学家波利亚 (George Polya) 早就提出过所谓 “波利亚罐子模型 (Polya Urn Model)”的问题。这个罐子模型的一个例子是:
有一个罐子,装满红色和绿色的球。红球和绿球的数目一样, 50/50。假设我们每次从罐子里随机拿出一个球,然后再把这个球和另外一个相同颜色的球放回罐子里.如果我们不断长期重复这个过程,最终罐子里的球的颜色分布会是什么样子的?
英国经济学家 Brian Arthur 和几名同事在 1983 年的论文里,计算分析这个例子得出的结论是:
1) 给足够长的时间,最终这两个不同颜色的球的比例,将会接近 100:0。
2) 最开始很难预测是红球,还是绿球会胜出. 受各种偶然因素影响, 都有可能。
3) 胜出者在过程的早期就会涌现。
4) 一旦领先,很难反转。
这里的关键是: 事先无法预测谁是胜者, 但在早期胜者开始涌现, 趋势不可逆转时,应果断加仓, 顺应趋势。
(6)
西班牙服装品牌 Zara, 采用的就是这种策略。他们意识到对于未来几个月流行服装款式的预测,他们其实不比别人强。大部分时装品牌公司, 试图预测下一季流行的款式,但一旦预测失误,大批服装在店里滞销,损失惨重。
Zara 派人定期到各个大规模购物中心,观察消费者的穿衣样式。再根据这些数据,设计大量各种款式,衣料和颜色的服装组合,随后迅速生产出小批量的成衣,送到零售店。
零售店的销售数据,马上可以告诉他们什么款式卖得好. 他们再据此信息, 迅速大规模生产卖得好的款式. Zara 可以在两周内, 完成对新款服装的设计/生产/运输/销售,覆盖全世界的所有角落。
喜欢我的文章,成为我的天使投资人吧,么么哒

相关资讯
更多 »



